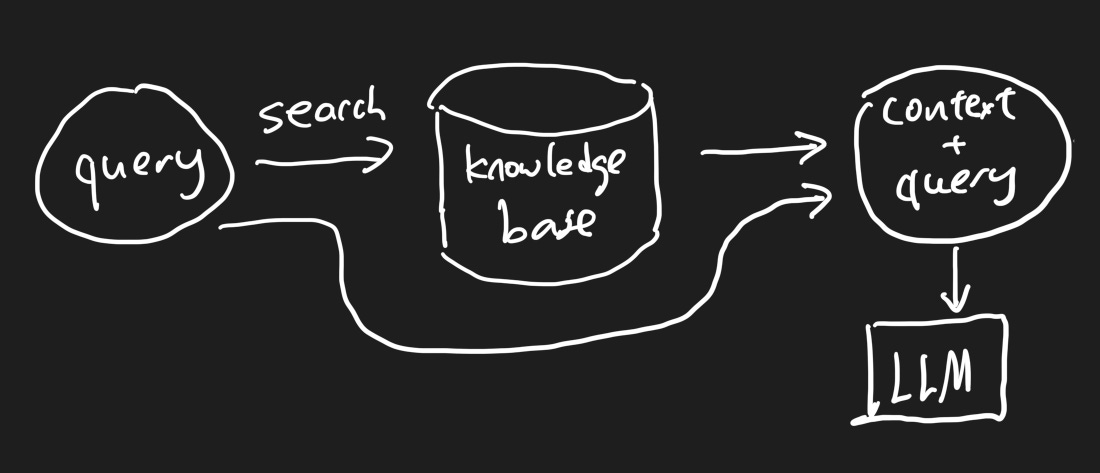
Retrieval-augmented generation (RAG) in simple words

Large language models (LLMs) can give us inaccurate or out of date answers.

Suppose we can provide additional contexts with our query, then it will be much easier for a LLM to answer questions — because we’ve already included the answer in the context it only needs to extract and summarise the context text.

But how can we provide the context in real time? That’s RAG. The idea is to run a search in a knowledge base that covers everything we care about. This is usually done using vector search in a vector database (that’s a topic for another time).

To put everything together, this is what it looks like to use RAG for LLM questions and answers.